Zeichenkodierung

Da in der frühen Phase der Computertechnologie die ersten Computersysteme in den westlichen Ländern entwickelt wurden, vor allem in den USA, konzentrierten sich die Entwickler von Textverarbeitungsprogrammen zunächst auf die Kodierung von Texten, die auf dem lateinischen Schriftsystem basierten.
- Eine Schrift besteht aus einer bestimmten Anzahl von Schriftzeichen.
- Diese Anzahl unterscheidet sich stark, je nach verwendetem Schriftsystem
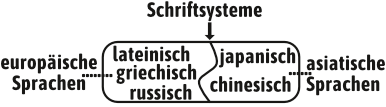
Während Schriftsysteme europäischer Sprachen, wie z.B. lateinisch, griechisch und russisch aus einer relativ geringen Anzahl von Schriftzeichen bestehen, ...
... enthalten die Schriftsysteme asiatischer Sprachen, wie z.B. chinesisch und japanisch eine wesentlich größere Anzahl von Schriftzeichen.
Computersysteme können nur Nullen und Einsen verarbeiten ...
... daher müssen bei der Textverarbeitung auf Computersystemen die Schriftzeichen erst in Nullen und Einsen umgewandelt ("kodiert") werden!
Dies bezeichnet man als "Zeichenkodierung".
Dazu wird jedem Schriftzeichen eine Zahlenreihe aus Nullen und Einsen zugeordnet...
Beispiel:
- die Zahlenreihe 1000001 steht für den großen Buchstaben "A"
- die Zahlenreihe 1100001 steht für den kleinen Buchstaben "a"
- die Zahlenreihe 1000010 steht für den großen Buchstaben "B"
- die Zahlenreihe 1100010 steht für den kleinen Buchstaben "b", usw.
Die einzelnen Nullen und Einsen werden "Bits" genannt...
... die Zahlenreihen in diesem Beispiel haben jeweils eine Länge von sieben Bit.
(Man spricht hier von einer "7-Bit-Kodierung".)
Bei einer Zahlenreihe, deren einzelne Zahlen zwei verschiedene Werte haben können (Null oder Eins) und die eine Länge von sieben Zahlen hat (sieben Bit), lassen sich 128 verschiedene Variationen bilden (2 hoch 7 = 128).
Die folgende Tabelle zeigt alle 128 möglichen Variationen, die sich bei einer Zahlenreihe von nur sieben Bit bilden lassen:
|
0000000 |
0000001 |
0000010 |
0000011 |
0000100 |
0000101 |
0000110 |
0000111 |
|
0001000 |
0001001 |
0001010 |
0001011 |
0001100 |
0001101 |
0001110 |
0001111 |
|
0010000 |
0010001 |
0010010 |
0010011 |
0010100 |
0010101 |
0010110 |
0010111 |
|
0011000 |
0011001 |
0011010 |
0011011 |
0011100 |
0011101 |
0011110 |
0011111 |
|
0100000 |
0100001 |
0100010 |
0100011 |
0100100 |
0100101 |
0100110 |
0100111 |
|
0101000 |
0101001 |
0101010 |
0101011 |
0101100 |
0101101 |
0101110 |
0101111 |
|
0110000 |
0110001 |
0110010 |
0110011 |
0110100 |
0110101 |
0110110 |
0110111 |
|
0111000 |
0111001 |
0111010 |
0111011 |
0111100 |
0111101 |
0111110 |
0111111 |
|
1000000 |
1000001 |
1000010 |
1000011 |
1000100 |
1000101 |
1000110 |
1000111 |
|
1001000 |
1001001 |
1001010 |
1001011 |
1001100 |
1001101 |
1001110 |
1001111 |
|
1010000 |
1010001 |
1010010 |
1010011 |
1010100 |
1010101 |
1010110 |
1010111 |
|
1011000 |
1011001 |
1011010 |
1011011 |
1011100 |
1011101 |
1011110 |
1011111 |
|
1100000 |
1100001 |
1100010 |
1100011 |
1100100 |
1100101 |
1100110 |
1100111 |
|
1101000 |
1101001 |
1101010 |
1101011 |
1101100 |
1101101 |
1101110 |
1101111 |
|
1110000 |
1110001 |
1110010 |
1110011 |
1110100 |
1110101 |
1110110 |
1110111 |
|
1111000 |
1111001 |
1111010 |
1111011 |
1111100 |
1111101 |
1111110 |
1111111 |
Ist die Zahlenreihe nur ein Bit länger, also acht Bit, sind schon 256 verschiedene Variationen möglich (2 hoch 8 = 256).
Für die englische Sprache reicht die "7-Bit-Kodierung" aus (128 Variationen). Damit lassen sich alle Groß- und Kleinbuchstaben, Sonderzeichen und Ziffern kodieren. Für die japanische Sprache bräuchte man jedoch längere Zahlenreihen.
Die Menge der zur Verfügung stehenden Schriftzeichen wird auch als "Zeichensatz" (engl.: "charset") oder als "Zeichenvorrat" bezeichnet.
Historischer Rückblick - Kodierungsvarianten

Das Hauptproblem bei der Kodierung von Textinformationen bestand in der frühen Phase der Computertechnologie darin, dass die verschiedenen Hersteller der Computersysteme, jeweils eigene Kodierungsvarianten entwickelten. ...mehr »
GML Verallgemeinernde Auszeichnungssprache

Auszeichnungen, engl. Markups, in einem Text dienten ursprünglich in der Druckindustrie dazu, dem Setzer Anweisungen zu geben, wie der Text in Absätze gegliedert, an welchen Stellen Bilder oder Tabellen... ...mehr »